Probabilistic Garbage Collection: How We Clean Up Stale Data Without a Cron Job
Probabilistic Garbage Collection: How We Clean Up Stale Data Without a Cron Job
When building web applications, there's always that one table that quietly grows forever. Temporary records, expired tokens, stale sessions — data that served its purpose and now just sits there, taking up space and slowing down queries.
The instinctive solution is to set up a scheduled job: a cron that runs every night, a background worker that fires every few hours, a queue task that sweeps through and deletes old rows. It works, but it adds infrastructure. You need to configure it, monitor it, handle failures, and document it for anyone who touches the project later.
There's a simpler approach — one that PHP has quietly used for its own session garbage collection for decades. We recently applied it to our custom ecommerce platform at TechAlb, and it's worth sharing.
The problem
While building our lightweight PHP ecommerce platform — a custom alternative to WooCommerce with full control over every layer — we had a cart_sessions table with no cleanup logic. Expired rows just accumulated forever. The only deletion happening was Cart::clear() at checkout, which only ever removed the current session's single row.
At low traffic, this is barely noticeable. At scale, it becomes a real problem: bloated tables, slower queries, and higher storage costs — all for data that has zero business value after it expires.
We needed a cleanup strategy. We didn't want to over-engineer it.
The pattern: probabilistic GC
The idea is simple. Instead of running cleanup on every request (expensive) or on a fixed schedule (extra infrastructure), you run it randomly on a small percentage of requests.
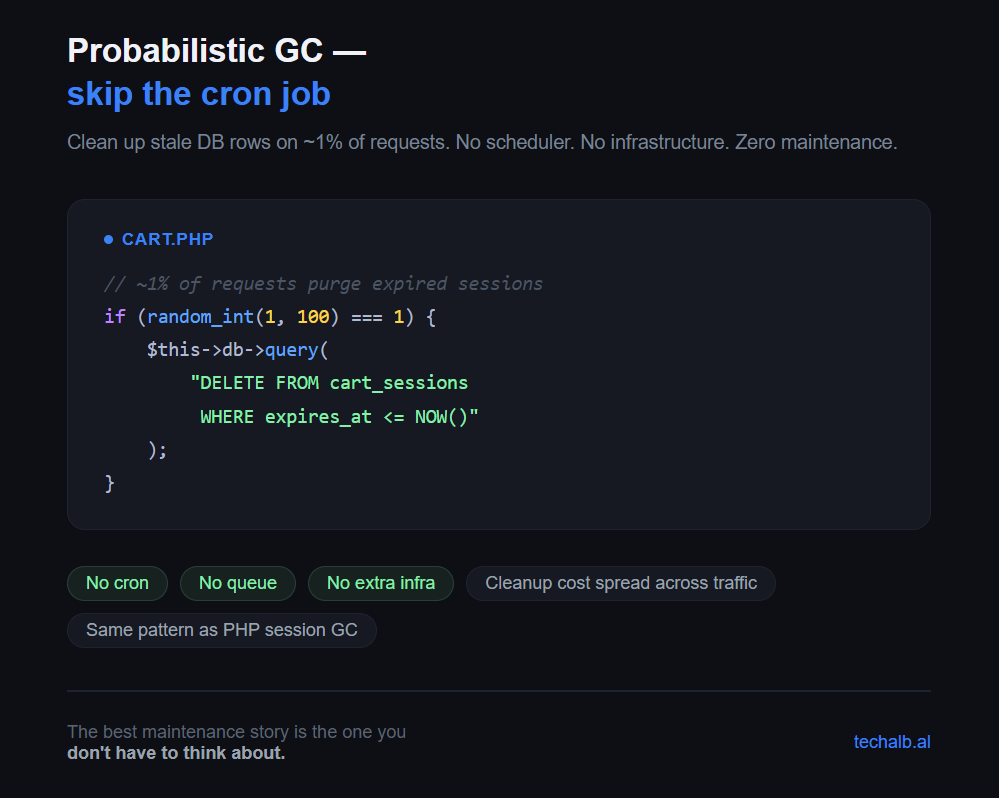
In our case, roughly 1% of Cart instantiations trigger a hard delete of all expired rows:
// Probabilistic GC: ~1% of requests purge expired rows
if (random_int(1, 100) === 1) {
$this->db->query(
"DELETE FROM cart_sessions WHERE expires_at <= NOW()"
);
}That's the entire implementation.
Why this works
At typical application traffic, 1% of requests is more than enough to keep the table clean. If your platform handles 500 cart instantiations per day, cleanup runs roughly 5 times. If it handles 10,000, cleanup runs around 100 times. The heavier the traffic, the more frequently the table gets swept — which is exactly when you need it most.
At low traffic, a handful of stale rows doesn't matter. The table stays small regardless.
The cost of the cleanup query is distributed across real user requests rather than concentrated in a scheduled job. For most workloads, the occasional extra DELETE is completely unnoticeable. And if a particular request happens to be the unlucky 1%, the query runs against an indexed expires_at column and returns immediately.
Where this pattern comes from
This isn't a new idea. PHP has used probabilistic garbage collection for its own session file management since early versions. The session.gc_probability and session.gc_divisor configuration options control exactly this: on any given request, PHP calculates whether to run session GC based on a configurable probability. By default, it's roughly 1%.
Most PHP developers have relied on this behaviour for years without ever thinking about it. The pattern just works quietly in the background.
The same logic applies cleanly to any ephemeral application-level data: cart sessions, password reset tokens, email verification codes, temporary upload handles, API rate limit windows, and similar records that have a natural expiry and no value after it passes.
What we paired it with
Alongside the probabilistic cleanup, we added a session expiry restore for logged-in customers.
When the session key lookup misses — because the session expired between visits — we fall back to the customer's most recent unexpired cart_sessions row by customer_id. This means a logged-in user who comes back after their session has expired doesn't lose their cart. They're seamlessly restored to where they left off.
Guests still lose their cart on session expiry. There's no identity to fall back on, and that's an acceptable trade-off. The experience for authenticated users — the ones most likely to return and complete a purchase — is protected.
When to use this approach
Probabilistic GC is a good fit when:
- The data is ephemeral and expires naturally (sessions, tokens, temporary records)
- Stale rows are harmless — they just waste space, they don't break anything
- You don't need precision cleanup (a few extra expired rows sitting around for a day is fine)
- The table is hit frequently enough that 1% of requests adds up to meaningful cleanup
It's not the right tool when you need guaranteed cleanup at a specific time — for example, deleting customer data for compliance purposes, or archiving financial records on a fixed schedule. For those cases, a proper scheduled job with monitoring is the right answer.
The result
Two fixes, zero infrastructure. The cart_sessions table stays lean without any dedicated maintenance. No cron to configure, no worker to monitor, no deployment step to enable cleanup on a new server.
It's the kind of solution that disappears into the codebase and just works — which is exactly what good infrastructure should do.
At TechAlb, we build custom web platforms and SaaS products with a focus on clean architecture and practical engineering decisions. If you're working on a similar project or want to see what we're building, visit us at techalb.al.


